[이진논리회귀] 타이타닉에서 당신이 생존할 확률은 얼마나 될까?
타이타닉에 탑승한 사람들은 성별, 나이, 국가, 티켓등급, 승차요금, 함께 탑승한 사람이 달랐다.
과거의 데이터를 통해 현재 내가 타이타닉에 탑승한다면 생존할 수 있을까의 여부를
머신러닝을 모델링하여 추측해보도록 하자.
타이타닉 데이터셋: https://www.kaggle.com/heptapod/titanic
Titanic
Suited for binary logistic regression
www.kaggle.com
# kaggle에서 발행한 API Token 입력
import os
os.environ['KAGGLE_USERNAME'] = 'username'
os.environ['KAGGLE_KEY'] = 'key'
# 데이터셋 불러오기
!kaggle datasets download -d heptapod/titanic
# 데이터셋 압축풀기(.csv 확장자로 생성됨)
!unzip titanic.zip
# 필요 라이브러리 import
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 상위 5개만 읽어오기
df = pd.read_csv('train_and_test2.csv')
df.head(5)
위와 같이 필요한 항목 외에 zero라고 되어있는 항목들은 데이터 가공이 필요하다.
# usecols로 사용하는 칼럼만 추출
df = pd.read_csv('train_and_test2.csv', usecols=[
'Age', # 나이
'Fare', # 승차 요금
'Sex', # 성별
'sibsp', # 타이타닉에 탑승한 형제자매, 배우자의 수
'Parch', # 타이타니게 탑승한 부모, 자식의 수
'Pclass', # 티켓 등급 (1, 2, 3등석)
'Embarked', # 탑승국
'2urvived' # 생존 여부 (0: 사망, 1: 생존)
])
df.head(5)
# 성별에 따른 생존여부 그래프
sns.countplot(x='Sex', hue='2urvived', data=df)
# 생존, 사망률 데이터
sns.countplot(x=df['2urvived'])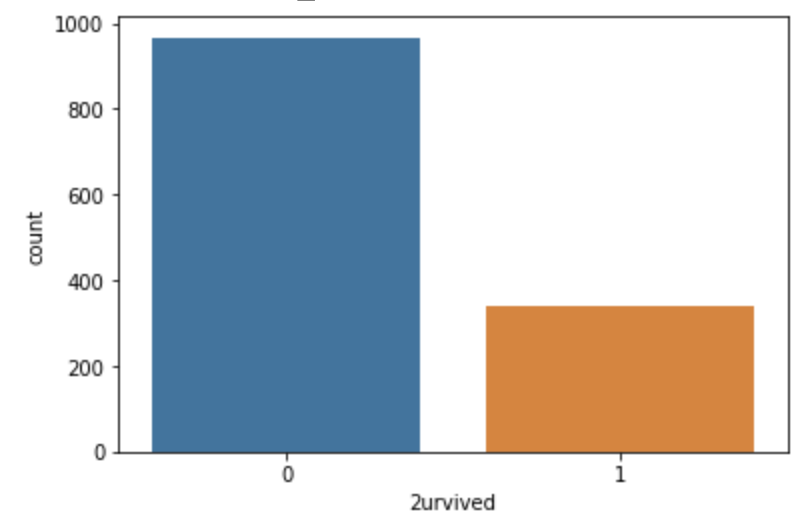
# 비어있는 값(null or na) 확인
# 출력값이 0이 아니면 비어있는 값이 있는 것
print(df.isnull().sum())
# null이 확인되면 drop시킨 뒤
# drop 반영 여부를 전체 데이터 수를 출력하여 확인
print(len(df))
df = df.dropna()
print(len(df))
# x데이터 분할
x_data = df.drop(columns=['2urvived'], axis=1)
x_data = x_data.astype(np.float32)
x_data.head(5)
# y데이터 분할
y_data = df[['2urvived']]
y_data = y_data.astype(np.float32)
y_data.head(5)데이터의 범위가 다 다름으로 데이터를 표준화 시켜 가공하는 작업이 필요하다.
데이터의 평균을 0으로 만들고 최대표준편차가 1이 되도록하는 방법이다.
이렇게 하면 범위가 다른 데이터들이 정규분포도 중앙으로 모이게 되어
학습하기에 좋은 데이터를 만들 수 있다.
# 데이터 표준화 가공
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
print(x_data.values[0])
print(x_data_scaled[0])
# 데이터 가공 후 학습데이터와 검증데이터를 분할
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
# 학습시킬 때 metrics을 사용하여 정확도(acc)도 함께 측정
model = Sequential([
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=20
)
# loss의 변화 그래프
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='train loss')
plt.xlabel('epochs')
plt.show()
epoch(에폭)이 반복될수록 loss 값이 줄어드는 것으로 보아
학습이 잘 되었음을 알 수 있다.
Age : 나이
Fare : 요금
Sex : 성별(남자는 0, 여자는 1)
sibsp : 배우자의 수
Parch : 자식의 수
Pclass : 티켓등급
Embarked : 탑승국(군집화하여 나눈 데이터셋)
위의 7가지 데이터를 array에 집어 넣으면
생존률을 예측 할 수 있다.
x_pred = np.array([[30, 50, 1, 1, 1, 1, 1]])
x_pred_scaled = scaler.transform(x_pred)
prediction = model.predict(x_pred_scaled)
print(prediction)나이는 30세, 운임은 50달러 지불, 성별은 여성,
배우자 1명, 자녀 1명, 1등급티켓, 탑승국 그룹1 일때의
생존률은 무려 82%이다.
성별이 남자이거나, 나이가 많아질수록, 지불한 운임이 낮아질수록,
티켓등급이 낮아질수록 생존률이 낮게 측정되는 사실을 알 수 있다.
타이타닉호에 내가 탔다면 생존할 수 있었을까를
느껴볼 수 있는 모델링을 마친다.