개발노트/kaggle 데이터를 활용한 머신러닝 예제
[다항논리회귀] 내가 마시는 와인을 기계로 분류할 수 있을까?
lovvepearl
2022. 1. 8. 13:56
와인의 종류는 일반적으로 색, 향, 맛, 질감, 용도, 양조법 등을
기준으로 구별한다고 한다.
와인을 판별하는 소믈리에도 직업으로 존재하는 것 처럼
다양한 와인을 구별해내는 것은 쉬운 일이 아니다.
우리에게는 와인의 여러 특성들을 바탕으로 와인을 3그룹으로
분류해놓은 데이터셋이 있다.
이 데이터셋을 바탕으로 내가 마시는 와인을 분류할 수 있는
기계를 학습시킬 수 있을까?
와인 데이터셋: https://www.kaggle.com/brynja/wineuci
Classifying wine varieties
Great practice for testing out different algorithms
www.kaggle.com
# kaggle API Token 입력
import os
os.environ['KAGGLE_USERNAME'] = 'username'
os.environ['KAGGLE_KEY'] = 'key'
# 데이터셋 불러오기(.zip 파일)
!kaggle datasets download -d brynja/wineuci
# 압축풀기(.csv 파일)
!unzip wineuci.zip
# 필요한 라이브러리 import
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
# 상위 5개 데이터 불러오기
df = pd.read_csv('Wine.csv')
df.head(5)
# names로 이름채워주기
df = pd.read_csv('Wine.csv', names=[
'name'
,'alcohol'
,'malicAcid'
,'ash'
,'ashalcalinity'
,'magnesium'
,'totalPhenols'
,'flavanoids'
,'nonFlavanoidPhenols'
,'proanthocyanins'
,'colorIntensity'
,'hue'
,'od280_od315'
,'proline'
])
df.head(5)
# wine name의 갯수 확인
sns.countplot(x=df['name'])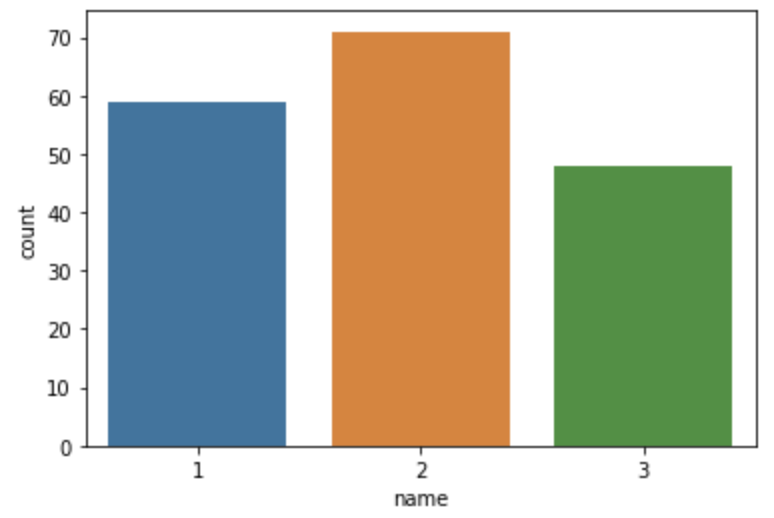
# null이나 na값이 있는지 확인하는 전처리
print(df.isnull().sum())0이 아닌 정수로 출력된다면, dropna()를 사용하여
null 값을 제거해주는 과정이 필요하다.
모두 0으로 출력된다면 null값이 없는 상태임으로
전처리 과정없이 데이터셋을 사용해도 무방하다.
# x 데이터 분할
x_data = df.drop(columns=['name'], axis=1)
x_data = x_data.astype(np.float32)
# y 데이터 분할
y_data = df[['name']]
y_data = y_data.astype(np.float32)
# 표준화 스케일러를 사용하여 데이터 표준화
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
# 기존의 데이터와 스케일된 데이터를 비교
print(x_data.values[0])
print(x_data_scaled[0])데이터의 범위나 크기가 다양할 경우 데이터 표준화하여
데이터의 평균을 0으로 최대표준편차를 1로 만들어준다.
표준화작업을 거쳐 스케일된 데이터는
그래프의 중앙으로 모이게 되어 학습하기 좋은 데이터가 된다.
# 원핫인코딩으로 name을 0과 1의 수로 만들어준다.
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0])
print(y_data_encoded[0])one hot encoding을 사용하여
결과값인 name의 1,2,3 그룹을 0과 1의 수로 만들어준다.
# 학습데이터와 검증데이터를 8:2의 비율로 분류한다.
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size=0.2, random_state=2021)
# 학습데이터와 검증데이터가 잘 나누어졌는지 크기를 출력한다.
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape) 이제 데이터를 가공하고 나누었으니 학습할 모델을 만들어보자.
model = Sequential([
Dense(3, activation='softmax')
])
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.02), metrics=['acc'])
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)결과값이 3개로 분류됨으로 dense는 3, 가중치로 %화 하여 결과값을 측정함으로 softmax를 사용한다.
결과값이 2개 이상임으로 categorical crossentrophy 사용하여 손실함수를 만든다.
결과값이 2개 이상임으로 categorical crossentrophy 사용하여 손실함수를 만든다.
경사하강법의 옵티마이져로 Adam을 사용하고 learning rate는 0.02로 설정한 뒤
정확도(acc)도 함께 측정하기 위해 metrics 를 추가한다.
model 그래프를 그릴 것이기 때문에 history로 정의해준다.

epoch이 반복될수록 loss값은 작아지고, acc(정확도)값은 커지는 것을 알 수 있다.
그래프를 통해 학습이 잘 되었는지 명확하게 확인해보자.
# loss값의 변화 그래프
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='train loss')
plt.xlabel('epochs')
plt.show()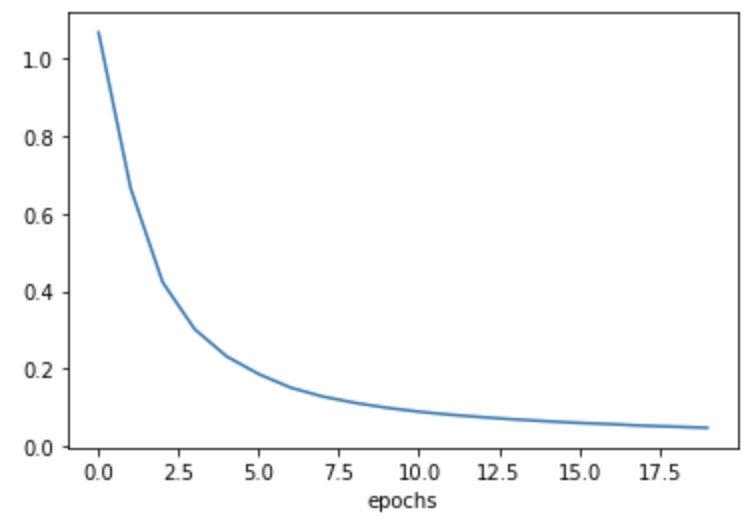
# loss값과 정확도를 함께 표현한 그래프
import pandas as pd
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.show()
이제, 만들어진 '와인판별 기계' 모델을 활용하여
내가 지금 먹는 와인이 어떤 이름으로 분류되는지 결과값을 얻을 수 있을 것이다.
이론상의 수치로는 그 깊이와 맛을 기계가
다 알 수는 없겠지만...🍷